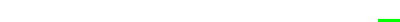
One way to achieve this is to transform the domain via a bijective function. For example, \(a+\frac{b-a}{1+e^{-\alpha t}}\) will transform \(]-\infty, +\infty[\) to ]a,b[. Then how should one choose \(\alpha\)?
A large \(\alpha\) will make tiny changes in \(t\) appear large. A simple rule is to ensure that \(t\) does not create large changes in the original range ]a,b[, for example we can make \(\alpha t \leq 1\), that is \( \alpha t= \frac{t-a}{b-a} \).

In practice, for example in the calibration of the Double-Heston model on real data, a naive \( \alpha=1 \) will converge to a RMSE of 0.79%, while our choice will converge to a RMSE of 0.50%. Both will however converge to the same solution if the initial guess is close enough to the real solution. Without any transform, the RMSE is also 0.50%. The difference in error might not seem large but this results in vastly different calibrated parameters. Introducing the transform can significantly change the calibration result, if not done carefully.
Another simpler way would be to just impose a cap/floor on the inputs, thus ensuring that nothing is evaluated where it does not make sense. In practice, it however will not always converge as well as the unconstrained problem: the gradient is not defined at the boundary. On the same data, the Schobel-Zhu, unconstrained converges with RMSE 1.08% while the transform converges to 1.22% and the cap/floor to 1.26%. The Schobel-Zhu example is more surprising since the initial guess, as well as the results are not so far:
| Initial volatility (v0) | 18.1961174789 |
| Long run volatility (theta) | 1 |
| Speed of mean reversion (kappa) | 101.2291161766 |
| Vol of vol (sigma) | 35.2221829015 |
| Correlation (rho) | -73.7995231799 |
| ERROR MEASURE | 1.0614889526 |
| Initial volatility (v0) | 17.1295934569 |
| Long run volatility (theta) | 1 |
| Speed of mean reversion (kappa) | 67.9818356373 |
| Vol of vol (sigma) | 30.8491256097 |
| Correlation (rho) | -74.614636128 |
| ERROR MEASURE | 1.2256421987 |
The initial guess is kappa=61% theta=11% sigma=26% v0=18% rho=-70%. Only the kappa is different in the two results, and the range on the kappa is (0,2000) (it is expressed in %), much larger than the result. In reality, theta is the issue (in (0,1000)). Forbidding a negative theta has an impact on how kappa is picked. The only way to be closer
Finally, a third way is to rely on a simple penalty: returning an arbitrary large number away from the boundary. In our examples this was no better than the transform or the cap/floor.
Trying out the various ways, it seemed that allowing meaningless parameters, as long as they work mathematically produced the best results with Levenberg-Marquardt, particularly, allowing for a negative theta in Schobel-Zhu made a difference.






















